
Ihr Kompass für den Feature-Dschungel. Von unseren Produktmanagern. Thema heute: Videokompression in IP-basierten Videoüberwachungssystemen (Teil 1 von 2). Von Christoph Konrad
Moderne Kompressionsalgorithmen versprechen bis zu 90 % Bandbreiten- und Speicherplatzersparnis bei der Übertragung und Archivierung von Videodaten. Wie werden derartige Einsparungen erreicht und werden derart komprimierte Aufnahmen noch den Qualitätsansprüchen gerecht?
Mehr Pixel, mehr Frames, mehr Streams – immer leistungsfähigere IP-basierte Videoüberwachungssysteme machen Netzwerken durch hohe Bitraten schwer zu schaffen. Sinkende Übertragungsgeschwindigkeiten und Verbindungsabbrüche können die Folge von Überlastung sein. Der Einsatz von effizienter Videokompression ist deshalb unerlässlich geworden. Oberstes Gebot dabei ist die maximale Reduzierung der Bitrate unter Beibehaltung der nötigen Bildqualität.
Intraframe- und Interframe-Kompression
Generell wird bei Videokompression zwischen zwei Kategorien unterschieden, der Intraframe- und der Interframe-Kompression. Bekanntester Vertreter der Intraframe-Kompression ist Motion JPEG (MJPEG).
Hier findet für jedes einzelne Bild eine unabhängige, verlustbehaftete Komprimierung als JPEG-Bild statt. Dabei leidet die Bildqualität mitunter enorm, was die Verwertbarkeit der Bilder gefährdet. Trotz dieser Kehrseite ist der Bandbreiten- und Speicherbedarf von MJPEG auch nach der Komprimierung vergleichsweise hoch, da für jedes Frame ein komplettes Bild mit allen Daten erzeugt und übertragen wird.
Die beiden größten Vorteile sind der geringe Rechenaufwand für Kodierung und Dekodierung sowie die hervorragende Kompatibilität mit Empfängern und Abspielgeräten.
Zwei heute noch in der Videosicherheit verwendete Vertreter der Interframe-Kompression sind H.264 (2003) und H.265 (2013).
Der entscheidende Unterschied zur Intraframe-Kompression ist die gruppenweise Betrachtung von Bildern. Jede Bildsequenz beginnt und endet mit kompletten Bildern, in denen sämtliche Bildinformationen enthalten sind.
Zwischen diesen sogenannten I-Frames befindet sich eine Reihe von Bildern, in denen, basierend auf ihren Vorgängern, lediglich die Veränderungen kodiert und übertragen werden. Diese sogenannten P-Frames (predictive-coded) beanspruchen nur einen Bruchteil des Speicherplatzes. Um weiteren Speicherplatz zu sparen, können zwischen zwei Gruppen von P-Frames weitere Sparmaßnahmen in Form von sogenannten B-Frames (bidirectionally-coded) vorgenommen werden.
Zusätzlich zum Vorgänger beziehen B-Frames auch eine Vorhersage auf das nachfolgende Frame mit ein und funktionieren so als eine Art Prüfsumme. Auf diese Weise entstehen zwischen zwei I-Frames Bildergruppen – groups of pictures (GOP). Aufgrund der Vielzahl von P- und B-Frames, in denen sämtliche redundanten Bildinformationen ausgelassen werden, lassen sich mit H.264 und H.265 extrem hohe Kompressionsraten erreichen.
Im direkten Vergleich beansprucht der Nachfolger H.265 in einem typischen Szenario rund 50 % weniger Bandbreite als H.264.
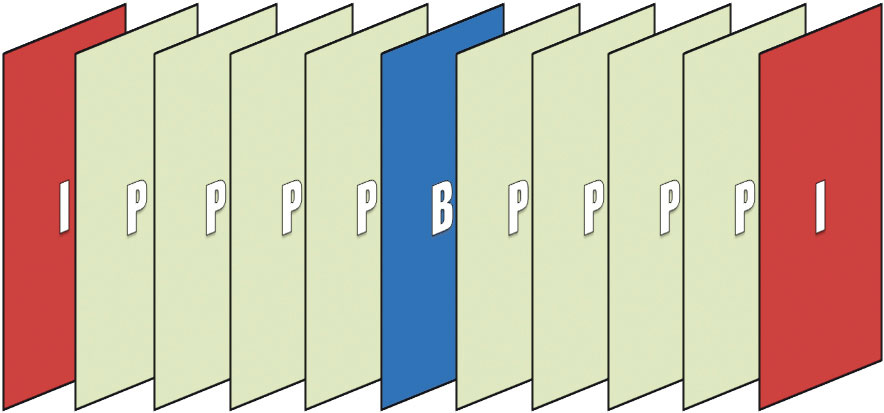
(Eine Group of Pictures besteht aus I-Frames sowie dazwischen liegenden P-Frames und B-Frames.)
In Teil 2 wird unter anderem näher auf die proprietäre Videokompression auf Basis von H.264 und H.265 bzw. Optimierungen wie Zipstream, Wisestream, Smartstream oder 265+ eingegangen und dar- auf, wie die wesentlichen Stellschrauben (Dynamisierung der Framerate, dynamische Region of Interest (ROI), dynamische Größe der Group of Pictures (GOP)) funktionieren.